
The internet is an oligopticon – a giant collecting machine, an idea that comes from Bruno Latour (of actor network theory renown). He describes the affordances of oligoptica in Reassembling the Social as follows; ‘sturdy but extremely narrow views of the (connected) whole are made possible–as long as connections hold’ – a good description of what the web is excellent at.
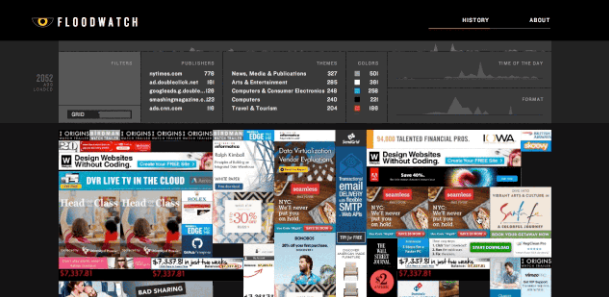
The Floodwatch project came to my attention in this context as an example of practical work that relates to browser history and what it reveals about people. It’s an app that tracks the ads served up on web pages visited and allows people to see exactly what online advertising they’ve been exposed to. The data is organised by volume, i.e. how many ads have been served up today, and type, i.e. what kind of advertising is cropping up in the browser. The people behind Floodwatch state three main aims; to reveal how advertisers track browsing behaviour, how they construct their version of online identity, and how they target their ads to individuals. They intend to build up a large repository of online advertising and use it to increase awareness and to empower users with as much information about advertising as advertisers have about them. In other words it’s about the balance of power between web users who unwittingly generate advertising opportunity and marketing agencies who exploit browser behaviour to sell their products and ideas.
The kinds of things online advertising does can only be described as intrusive. Individual browser activity is carefully tracked and sold on to advertising companies who place ads that they deem appropriate. youronlinechoices is a website that reveals which companies are currently serving up advertising to your browser. The thinking here operationalises Eli Pariser’s Filter Bubble concept. If everything you see online is a result of complex algorithmic analysis of your personal preferences and habits made available to advertising and search companies, you will only ever see what you’re already interested in and what aligns with your current interests. The problem with that is it creates a kind of bubble of personalisation around people, preventing serendipitous discovery or exposure to new ideas. Important, but not personal to the individual, news, such as climate change or homelessness drops out of view. youronlinechoices allows web users to turn off personalised advertising and consequently escape from an important influence of the filter bubble. You still see advertising but it isn’t based on your previously reported behaviour and can’t be targeted to your interests. The Network Advertising Initiative offers a similar tool they call a consumer opt-out that allows people to choose which companies can serve up personally targeted ads.
Krishnamurty and Wills show here how social networking sites leak your personal information to advertising companies, without telling users or asking permission, so those advertisers can see where you go online, what you do when you’re there, what you read (and often what you think about it as revealed in your comments or status updates) and who you’re connected to. The Electronic Frontier Foundation explain here how it’s done. Lots of these techniques involve cookies and the standard advice is to manage your cookie settings within the browser. Panopticlick is an EFF web app that tests how unique your browser is (by tracking user agent strings) and therefore how easily identifiable to advertisers, or search engines, or the secret police, you are when online. The EFF use a measure of information expressed in bits to quantify how identifiable people are from their browser alone – note this takes no account of cookies, IP addresses or HTTP referral. User agent strings will commonly hold 5-15 bits of identifying information – not usually enough to identify an individual. But triangulated with browser extensions you might have installed, or even web fonts active, you can be identified very easily.
All of this has profound implications for what people unwittingly do online and how that behaviour is reported. The argument I make in my research is that global corporations have a very detailed picture of what people do online that web users do not have access to. Without detailed logs people have no access to the kind of information available to advertisers. We have no idea who else has access to the data either legally or not, but we can have a pretty good guess (PRISM, Boundless Informant etc). The nature of computer intelligence and algorithmic analysis is that it’s thorough, fast, and indiscriminate and that it’s emergent – it builds up over time with increasing detail. The questions I have about things like Floodwatch, Panopticlick, and youronlinechoices is; they don’t offer any suggestions about what actions people should take, they appeal, and are visible to, people who already know about web tracking, and they are highly algorithmic, and therefore opaque, in nature. Browser history comics by contrast are intended to democritise access to records of web activity. They are a holistic, narratively structured, non algorithmic way of reporting and accounting for browser behaviour.
virtuality
ads not seen
